
Developers Corner
FAST-HEP was founded as a platform for experimentation and innovation in High Energy Physics analysis software. In many ways, we’ve been fortunate — early successes and real-world adoption have validated our ideas. However, this has also made it more difficult to introduce breaking changes or rethink foundational design choices.
As we continue to evolve, we are committed to supporting both stable, production-ready workflows and experimental, forward-looking developments. This balance is central to everything we do. However, we also need to minimise the maintenance burden of our packages, so that we can focus on innovation and new features.
This section outlines our current development efforts, their motivations, and goals.
As FAST-HEP has grown, so have the demands placed on its architecture. While the current system has served many use cases well, several limitations now hinder both innovation and maintainability. The rewrite aims to address these by modernising the core design.
- Enable workflows currently unsupported by tools like coffea, including multi-tree analyses.
- Move from hard-coded YAML logic to a modular interpretation layer (e.g. using omegaconf) for flexibility and user customisation.
- Refactor the stack to be modular and plugin-driven, allowing easy extension for features like:
- Caching
- Portability
- Custom monitoring
- Separate external dependencies more cleanly to reduce coupling and improve testability.
- Replace legacy components whose design has become outdated and difficult to maintain.
- Build on stable, scalable technologies such as Dask to serve as a general-purpose backend.
- Clearly separate the user-facing API from the execution backend, enabling easier testing and development.
- Provide a richer and more intuitive API that works seamlessly in Jupyter notebooks, not just via CLI.
- Simplify injection of provenance and metadata for reproducible workflows.
- Allow deeper access into the stack when needed, without sacrificing high-level simplicity.
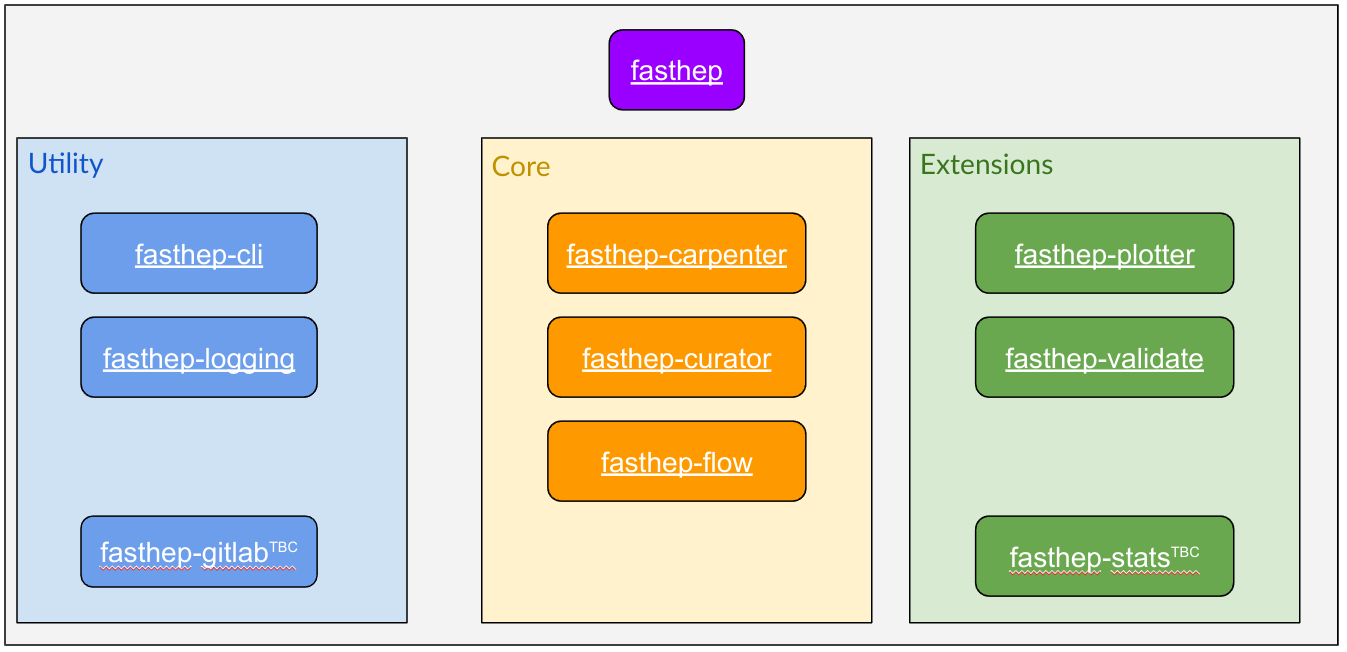
To ensure production workflows remain stable and uninterrupted—while also improving consistency and visibility across the ecosystem—all fast-* packages will undergo a planned restructure and renaming process.
- All
fast-*packages will be renamed to follow thefasthep-*naming convention. scikit-validatewill becomefasthep-validate.- Three new packages will be introduced:
fasthep-cli: A unified command-line interface replacing the individual CLIs in existingfast-*packages.fasthep-workshop: A curated set of Jupyter notebooks demonstrating real-world usage in a workshop-style format.fasthep: A meta-package simplifying installation of the entire FAST-HEP stack — or subsets of it.
Key packages will be restructured for better integration and usability within the new architecture:
fasthep-plotter,fasthep-validate, andfasthep-statswill be rewritten as tasks compatible with theflowpackage.- All general-purpose utility functions will be consolidated under
fasthep-carpenter, which will serve as the toolbox for analysis building blocks.
These changes will also improve the use in Jupyter notebooks, making it easier to develop and test workflows interactively.
Planned extensions will be reimagined as stages or plugins for fasthep-carpenter, aligning them with the modular workflow philosophy and simplifying integration.
Note: Not all of these packages currently exist. For the latest status and details, see the package restructure page.
The current workflow description in fasthep-flow presents several challenges that limit extensibility, maintainability, and long-term sustainability. This section outlines the problems and our planned improvements.
Tight Coupling to Backends The existing workflow logic is embedded directly in backend implementations (e.g. Dask, Coffea). This tight coupling makes it difficult to extend to new backends or modify existing logic without cascading changes.
Lack of Versioning The workflow description lacks robust versioning, making it hard to track changes over time, ensure reproducibility, or maintain backward compatibility.
Limited Extensibility Adding support for new features or integrating new backends is cumbersome under the current design, limiting innovation and adoption.
To address these issues, we propose introducing a standardised, backend-agnostic workflow description. Rather than encoding execution logic directly in the backends, workflows will be defined in a declarative format—structured around execution units (e.g. tasks and plugins).
These workflow definitions will be interpreted by converters, which are responsible for translating the abstract workflow into backend-specific compute graphs and data-passing logic. Examples will be provided for Hamilton, Dask, Parsl, and Coffea. Additionally, users will be able to implement and maintain their own converters independently of the core FAST-HEP packages.
Benefits of this approach include:
- Improved maintainability and flexibility by isolating backend-specific logic.
- Independent evolution of the workflow description, allowing the addition of new features without breaking existing converters.
- Reproducibility and compatibility through versioned converters and configuration formats.
- Support for a growing ecosystem, where external contributors can provide and share new backend integrations.
As FAST-HEP has grown, support for edge cases and non-standard workflows has led to code complexity and technical debt. To streamline development and reduce ongoing maintenance costs, we will:
- Remove unused code and deprecated features not required for production workflows.
- Refactor components into more modular, testable, and maintainable units.
- Introduce full configuration versioning to enable consistent tracking of changes and better compatibility management.
- Adopt static typing and type hints across the codebase to catch bugs earlier and improve overall code quality.
Several key features—including simple GPU workflows, multi-tree analysis, and integration with modern tools like uproot5—were made possible through the IRIS Digital Assets grant. However, the existing architecture places limitations on how far these innovations can go.
The upcoming modernisation and package restructure will enable us to fully realise and extend these capabilities:
Task-Level GPU Workflows Workflows will be able to dynamically accelerate specific tasks using GPUs, focusing compute resources on the most demanding steps and enabling parallel execution at scale.
Comprehensive Multi-Tree Analysis We will support complex workflows operating across multiple trees or datasets—an increasingly common requirement in modern HEP analyses.
Seamless Integration with Modern Ecosystem Tools Enhanced compatibility and tighter integration with powerful libraries such as:
boost-histogramfor efficient, high-performance histogramming.parquetfor modern, compressed, columnar data storage.uproot5for writing ROOT filesSnakeMakeandHamiltonfor workflow management.
Interface to SWIFT-HEP A new interface to
SWIFT-HEPwill allow direct use of cutting-edge developments, including integration with the Virtual Analysis Facility.
These improvements will ensure FAST-HEP remains aligned with modern analysis practices, offering a robust foundation for performant, flexible, and scalable HEP workflows.
The planned improvements to FAST-HEP mark a significant step forward in making high-energy physics (HEP) analysis tools more maintainable, extensible, and reproducible.
By decoupling the workflow description from execution backends, introducing a more modular and versioned architecture, and consolidating packages under a coherent fasthep-* naming scheme, we aim to create a robust foundation for future development and community collaboration.
New functionality—enabled by architectural changes and past support from initiatives like the IRIS Digital Assets grant—will unlock more advanced use cases, such as GPU-accelerated tasks, multi-tree analysis, and deeper integration with tools like uproot5, boost-histogram, and SWIFT-HEP.
Ultimately, these changes are driven by the needs of modern HEP research: scalable workflows, reproducible results, and a developer-friendly ecosystem. With this foundation, FAST-HEP is well-positioned to grow as a core part of the HEP software landscape.